R言語を使いWeb教材「ハンバーガーショップで学ぶ楽しい統計学」1の「カイ2乗検定」について進めていきます(第3回)。
チキンの売り上げは少ないのか
ワクワクとモグモグの、ポテトとチキンの1日の売り上げ個数を調べ、その個数は次の表(クロス集計表)にする。
> クロス集計表<-matrix(c(435,265,165,135),2,2)
> rownames(クロス集計表)<-c("ワクワクバーガー","モグモグバーガー")
> colnames(クロス集計表)<-c("ポテト","チキン")
> クロス集計表
ポテト チキン
ワクワクバーガー 435 165
モグモグバーガー 265 135
仮説を設定
帰無仮説H0:チキンとポテトの売り上げの割合に関して、モグモグとワクワクの間に差はない。→2つの変数は独立(連関がない)である。
対立仮説H1:
チキンとポテトの売り上げの割合に関して、モグモグとワクワクの間に差はある。→2つの変数は独立(連関がある)ではない。
期待度数の算出
先ほどの観測度数を記したクロス集計表に周辺度数と総度数を加えて記すと以下のようになる。
ポテト | チキン | 計(列) | |
ワクワクバーガー | 435 | 165 | 600 |
モグモグバーガー | 265 | 135 | 400 |
計(行) | 700 | 300 | 1,000 |
(行の計および列の計を周辺度数といい、特に行と列の計が交わる値=1,000を総度数という)。
期待度数は差がないという帰無仮説のもとで、どのくらいの度数をとるのか期待される度数をいうので、「(セルが属する行の周辺度数×セルが属する列の周辺度数)÷総度数」で求まる。
> 期待度1行1列<-600*700/1000
> 期待度1行2列<-600*300/1000
> 期待度2行1列<-400*700/1000
> 期待度2行2列<-400*300/1000
> 期待度数<-c(期待度1行1列,期待度1行2列,期待度2行1列,期待度2行2列)
> 期待度数
[1] 420 180 280 120
計算した期待度数を表に入れて示すと以下のようになる。
ポテト | チキン | 計(列) | |
ワクワクバーガー | 420 | 180 | 600 |
モグモグバーガー | 280 | 120 | 400 |
計(行) | 700 | 300 | 1,000 |
カイ2乗値とカイ2乗分布
観測度数と期待度数のずれを数値にする(カイ二乗値の計算)
カイ二乗値は「
(((観測度数-期待度数)の2乗)÷期待度数)の総和」で求まる。
> 観測度数<-c(435,165,265,135)
> 観測度数
[1] 435 165 265 135
> カイ二乗<-sum((観測度数-期待度数)^2/期待度数)
> カイ二乗
[1] 4.464286
カイ二乗分布
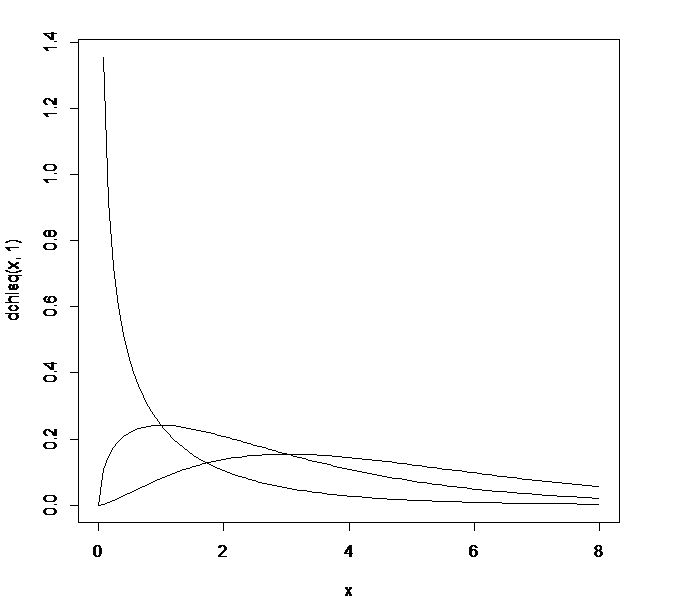
自由度を変化させた(df=1→3→5)ときのカイ二乗分布の変化を示す(正規分布やt分布のように0を中心にした左右対称の分布にはならないが、自由度が大きくなると左右対称の形に近づく)。
> curve(dchisq(x,1),0,8)
> curve(dchisq(x,3),0,8,add=TRUE)
> curve(dchisq(x,5),0,8,add=TRUE)
カイ2乗検定
自由度(df: degrees of freedom)は、一般的には行と列がある二次元の表の場合の自由度は「(行の数-1)×(列の数-1)」と示される。 つまりポテト・チキンまたは、ワクワク・モグモグの 1つの値が決まれば、残りは自動的にきまるので(2-1)* (2-1)=1となる。
確率を求める
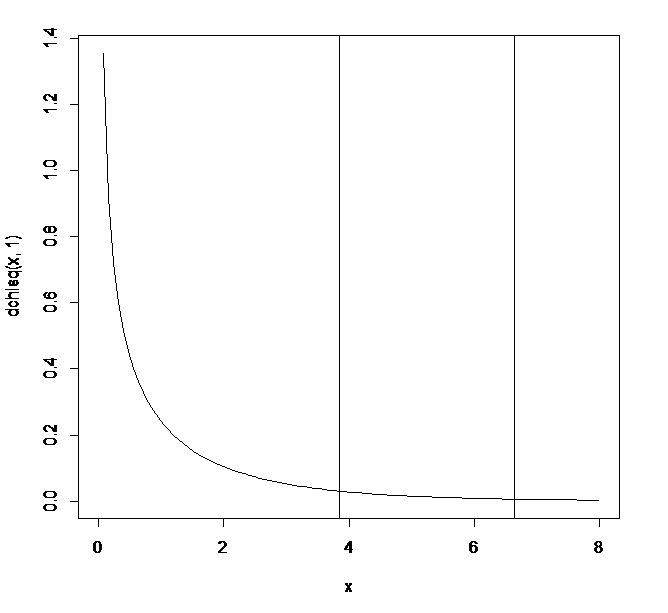
有意水準5%と1%を求める。
> qchisq(0.95,1) #自由度1のカイ二乗分布で下側0.95となるカイ二乗の値を求める
[1] 3.841459
> qchisq(0.05,1,lower.tail=FALSE) #自由度1のカイ二乗分布で上側0.05となるカイ二乗の値を求める
[1] 3.841459
> qchisq(0.99,1) #自由度1のカイ二乗分布で下側0.99となるカイ二乗の値を求める
[1] 6.634897
> qchisq(0.01,1,lower.tail=FALSE) #自由度1のカイ二乗分布で上側0.01となるカイ二乗の値を求める
[1] 6.634897
自由度1で有意水準5%と1%を図示すると以下のようになる。
curve(dchisq(x,1),0,8)
abline(v=qchisq(0.05,1,lower.tail=FALSE))
abline(v=qchisq(0.01,1,lower.tail=FALSE))
仮説検定をする
今回は「有意水準として5%をとるとする」とあるので、棄却域はカイ二乗(=
4.464286)より5%の場合の棄却域に入るため、帰無仮説は棄却され、対立仮説を採択します。つまり、「
ワクワクとモグモグではポテトとチキン売り上げの割合に差がある」といいう結論になります。
Rの関数を使いχ2(カイ二乗)検定をする
カイ二乗検定を関数chisq.test()で一発検定し、correct=FALSEはデフォルトで実行される連続性の補正を行わない。
> chisq.test(クロス集計表,correct=FALSE)
Pearson's Chi-squared test
data: クロス集計表
X-squared = 4.4643, df = 1, p-value = 0.03461
p値(p-value)は、帰無仮説が正しいという仮定のもので計算した値(今回はカイ二乗)について、それ以上で得られる確率のこと。
カイ二乗のp値の計算は以下のように行う(なおカイ二乗値の後には自由度を入れ、上側確率の場合は更にその後にcorrect=FALSEを加える)。
> pchisq(カイ二乗,1,lower.tail=FALSE)
[1] 0.03461056
有意水準5%(0.05)の値より小さいのでp値からも帰無仮説が棄却されることがわかります。
- Web教材「ハンバーガーショップで学ぶ楽しい統計学」第3章 カイ2乗検定 http://kogolab.chillout.jp/elearn/hamburger/chap3/sec0.html